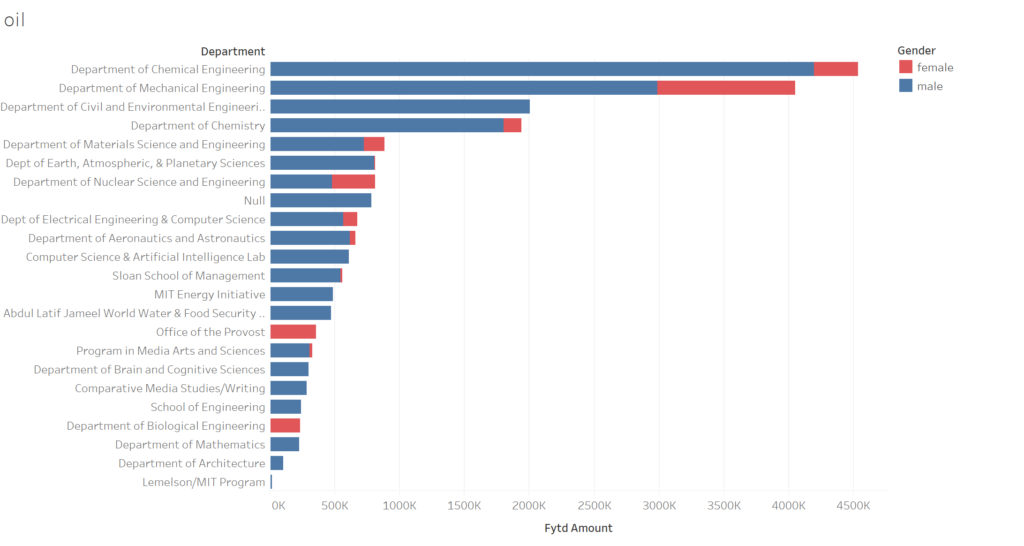
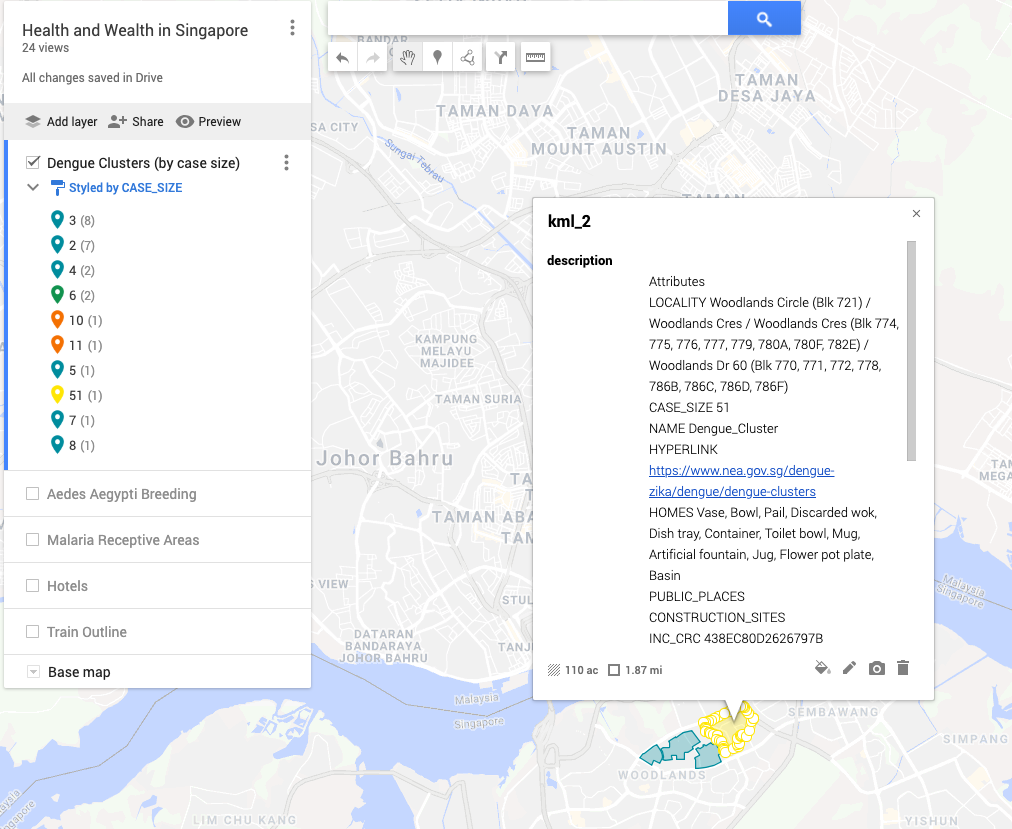
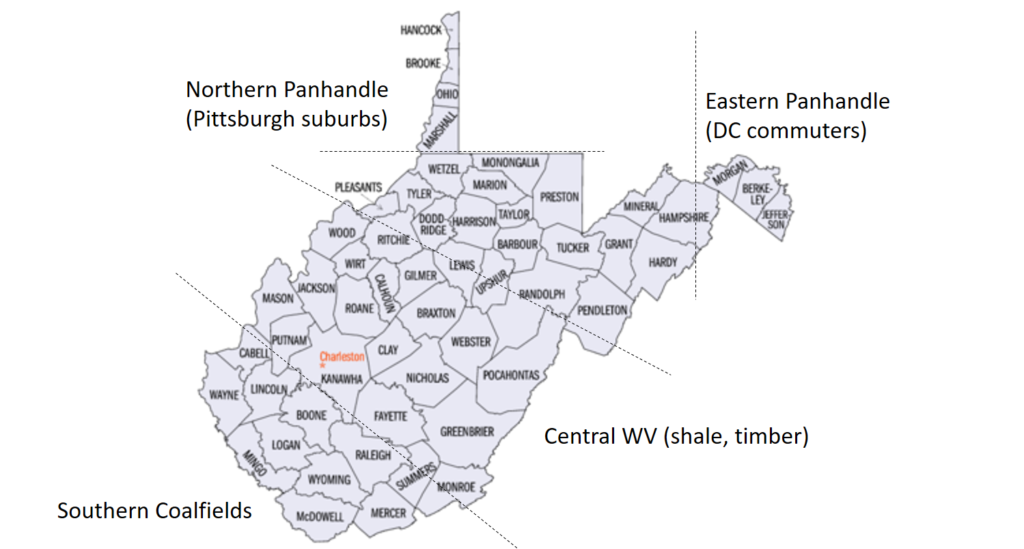
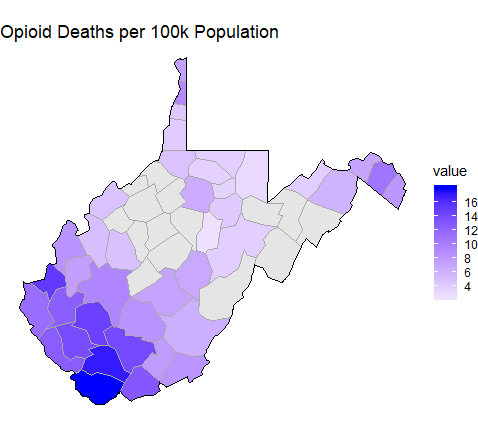
The big picture
By Tuesday (21st of Feb) early morning, I tracked about 5.5 days of media usage totalling about 46.6 hours. I used 4 distinct sources of technology – Macbook Air, iPhone, Echo and paper. I used RescueTime to track usage on my laptop, Moment app to track usage on my phone and my good ol’ brain for the rest.
Using a top down approach, following was my overall media usage broken down by category:
 Source: RescueTime, Moment and personal data collected; chart built using Plot.ly
Source: RescueTime, Moment and personal data collected; chart built using Plot.ly
My media usage amounts to about 35% of my day (46.6 hours out of 5.5 days tracked). I spend the rest of my day commuting (without using media), in class, meetings, running errands, socializing, working out and sleeping. Given sleeping forms a third of my day (7 hours per day), my media consumption though significant is not a very bad statistic.
Takeaway 1: Multiple media sources form the 35% daily average media usage for a multitude of tasks
From the smallest to the largest source of media consumption…
Echo (daily average ~ 10 minutes)

Echo has been primary news source in the last week. I listen to headlines and short articles from NY times, WSJ, BBC and Economist as I get ready for the day.
Usually I try to scroll through my NY times, WSJ and BBC phone apps but the usage has been minimal in the last week.My news app usage varies but I find myself needing 15-20 minutes to go through all my news apps during the morning but I haven’t allotted the time since being back to school. I usually listen to news podcasts (economist and WSJ) on my walk to school, but given the snow / weekends my podcast listening has been non-existent.
Takeaway 2: Consume news (mostly headlines) during commute / multi-tasking
Print Media (daily average ~ 1-2 hours)
My print media usage is usually restricted for class readings – articles and cases. Given I am taking 5 courses this semester, all of which are qualitative, it makes sense to read 1-2 hours on a daily basis to prepare for my average 2 classes per day.
Takeaway 3: Print media restricted for coursework ~ associating print with serious media consumption
iPhone (daily average ~ 1.6 hours)
 While on average my iPhone usage is around 1.6 hours per week, following is a snapshot of my phone usage for a single day which is reflective of my day-day consumption. I learnt a lot about my phone usage habits and they were pretty consistent with my love of productivity and addictive Instagram usage habits.
While on average my iPhone usage is around 1.6 hours per week, following is a snapshot of my phone usage for a single day which is reflective of my day-day consumption. I learnt a lot about my phone usage habits and they were pretty consistent with my love of productivity and addictive Instagram usage habits.
Using Moment app on my iPhone, I was able to track app usage by minute, location and time of day. Following is a snapshot for last Monday (20th Feb):

1. Throughout the day, I check my phone 60 times, that means on average once every 17 minutes (excluding 7 hours for uninterrupted sleep time) … clearly a sign of addiction. I used the phone, per check, anywhere from 2 minutes to 44 minutes with a median of 3 minutes, which reflects my fairly short attention span.
2. Home screen – I spend majority of my time using the home and lock screen, which is where I receive alerts from my various news apps. This indicates my sad habit of consuming news headlines in terms of alerts (I mostly get updates from news apps and outlook and check my phone periodically as my phone is always on night mode).
3. Productivity, productivity, productivity apps – sweat, outlook, weather, notes, app store – my focus has been on working out, emailing / checking calendar, taking quick notes, checking weather and getting more apps to improve my productivity. I am not surprised or shocked by the usage numbers given I feel I am at a minimal time per app.
4. Social networking – Facebook, Instagram, Whatsapp – my Instagram usage is alarming. I have a preference for visual media consumption especially given my interest in following influencers in food, travel, health and fitness space. I feel Instagram is best suited to connect with influencers and brands I like.
Takeaway 4: Spend time reading in-depth investigative news articles rather than consuming news updates
Macbook (daily average ~ 3.8 hours)

I primarily love using my laptop the most because of the screen space and find it most convenient to use the laptop for both work and entertainment.
- Too much entertainment – According to my RescueTime dashboard, I spend 40% of my time on entertainment and rest on more productive applications like outlook and excel. Following is a screenshot of my overall usage last week by top applications used:
 Source: RescueTime dashboard
Source: RescueTime dashboard
- Timeline analysis – I created the following heatmap for my three main categories (entertainment, communication and design) to understand my hourly usage patterns across the last few days. The richer the color, the more time spent in that category.

Source: RescueTime data; heatmap built with excel
My main takeaway from my usage indicates that I have productive work hours from 9 am till 8 pm and during the rest of the time I waste my time consuming Netflix for entertainment purposes.
Takeaway 5: Give up Netflix!!!!
Overall, I notice my media consumption is very self-centered in serving my own interests. I would be curious to learn how to a non-participatory citizen, such as myself, to be influenced by subjects outside my interest areas and how these topics could enrich my life.