
This was an interesting and challenging assignment. Defining what to include as media consumption, figuring out how to measure it, and summarizing the mass of data in a reasonable form were some of the design decisions I had to make. I decided to provide qualitative observations on my offline and mobile access and then try to “deep dive” into my web history to gain further insights into what I consume.
Offline Media
-
Print: I don’t currently subscribe to any newspapers or magazines. I picked up and skimmed the MIT student newspaper (the Tech) and the newsletter of the graduate dorm I live in (Sidney Pacific). The elevators of Sidney Pacific have a wide array of posters that I inevitably see every day. A common characteristic of the print media I consume is that they are simply there.

Elevator posters on February 8.
-
Television: I watched the Olympic opening ceremonies on Friday, February 7 for two to three hours. I also turned on the television at a few points this week, out of habit. Usually, I channel surf or leave the television on as background noise. Possibly because of the way that television is architected — it’s really easy to press the channel-up or channel-down button — I probably get a wider variety and range of perspectives than I do when I’m on the Internet. For example, this week, I’ve watched at least of a few minutes of PBS, the three major American networks, the Discovery Channel, Fox News, and C-SPAN.
-
Radio/Music: I didn’t listen to the radio this week. I usually listen to NPR if I drive, but I didn’t drive this week. I used Songza (a website like Pandora that gives personalized music recommendations) to listen to music on my phone and computer.
Mobile
A substantial amount of my media consumption is on my phone. Unfortunately, I didn’t find a good tool to automatically track my mobile usage or automatically take screenshots; in hindsight, capturing my browsing history might have worked to some extent, but it wouldn’t have been able to capture all of my usage through various apps. It’s my hope that my deep dive into my desktop Internet usage will capture some of these patterns.
A key exception is Facebook. A few weeks ago, to reduce distractions on my computer, I decided to logout of Facebook from my computer and access it only on my phone. I think that it has been a successful experiment — I’ve only logged in to Facebook on a couple of occasions. On my phone, I accessed Facebook on a daily basis and generally click on a few links on my news feed.
Desktop/Internet
RescueTime
As a first step, I used RescueTime to measure my computer activity. As illustrated below, it provided an indication of when I’m on the computer and the types of activities I do. It seems like a lot of my most productive hours are in the early evenings and early hours of the morning.
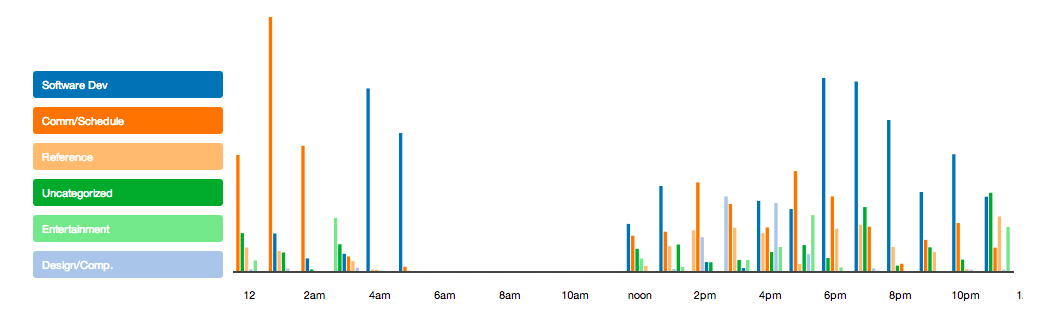
Usage by hour of day
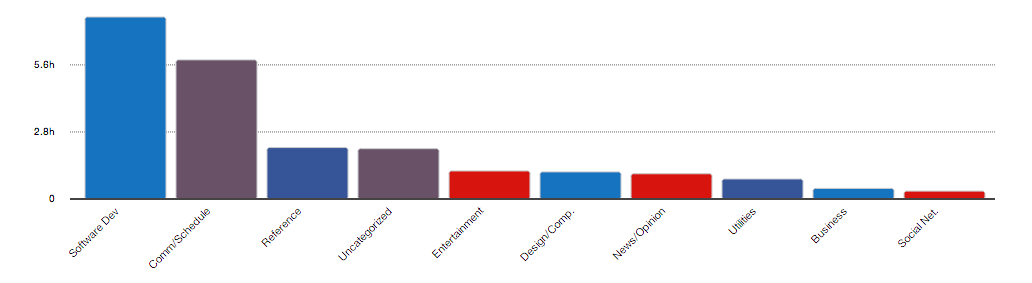
Usage by category
RescueTime also provided a breakdown of my news and entertainment consumption:
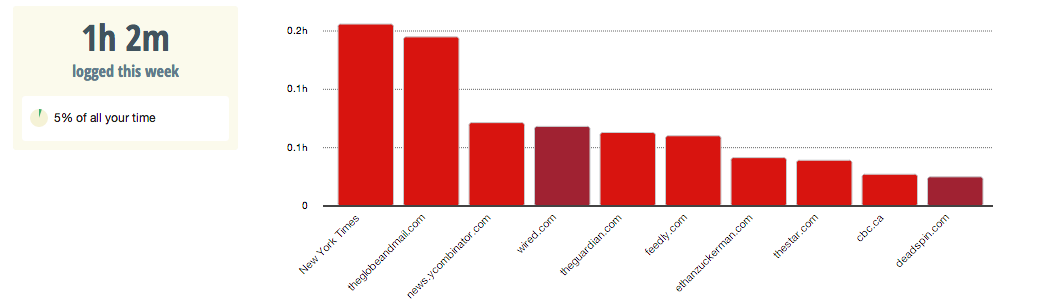
News consumption
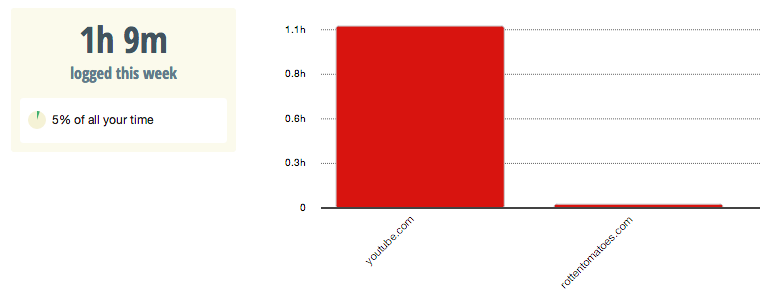
Entertainment consumption
Reflections
-
I’m pretty surprised by how much I read Canadian media — I usually go to these URLs as a distraction.
-
In contrast, I “stumble upon” other kinds of physical offline media more often.
-
It’s interesting to think about how to think about and capture offline interactions and media consumption. The ways that I can think of, such as written or audio journaling or taking photos regularly, seem fairly disruptive and invasive.
-
It takes time and effort to trace one’s own media consumption. Notably, large Internet companies — Google, Facebook, Amazon, Twitter, and others — have substantial infrastructure and resources capturing every click and action of their users. It is interesting to think about what insights can be gleaned from that data, along with the limitations of what they can infer about human behavior and preferences.