Note: This is maybe more detailed and involved than needed, so apologies for the length of the post. But I’m submitting a similar version of this proposal for a Knight Prototype Fund grant, so I’d be grateful for any feedback or suggestions.
What is your project?
We are producing a series of multimedia diaries that take advantage of wearable technology. The core of the project is the creation of an app for Google Glass that automatically records 10 seconds of video every few minutes and automatically interviews the subject throughout the day by displaying questions and recording the answers.
For the initial phase of the project, we will choose participants with particularly compelling circumstances and loan them Google Glass, and a producer/editor will work closely with each subject to coach them through the process, explain the privacy implications, and obtain permissions where appropriate. The resulting Web videos will be short – just 2 or 3 minutes each – to give viewers a peek into the day in the life of another person, from their first-person perspective.
In a later phase, we hope to add a system that can automatically assemble the clips into a draft piece and let users do simple editing to cut or reorder the clips. That way, the wearable diaries can be created without the help of a human editor. The app will be free to encourage as many people as possible to participate.
Who is the audience for the project? How will they be impacted?
Our approach is modeled loosely on the Radio Diaries project, a non-profit effort that gives people audio recorders to document their lives (though we have no affiliation with that project). Pieces from the Radio Diaries project reached a wide audience through broadcasts on NPR stations and were also distributed online and were a critical and popular success.
We are reaching out to traditional news outlets (newspaper and magazine Web sites) for possible partnerships to publish pieces made through the Wearable Diaries project. We will also post the pieces on our own Web site, with the hope that those who watch one of the diaries will be curious to see others in the series.
The stories are simple in their structure, but we believe their impact can be profound. By documenting the lives of many types of people in a short and sharable format, showing the similarities and differences in a diverse group of people, we hope to promote empathy and understanding of difference – as well as simply telling compelling stories.
What has come before?
This project can be situated in a long history of “life-logging” efforts, which have been proposed since the earliest days of wearable computers. A 2006 Media Lab project called InSense, for instance, let users make personal multimedia stories with a bulky camera and computer strapped onto a user’s chest. (http://hd.media.mit.edu/tech-reports/TR-599.pdf) Our effort takes advtange of the latest technology, which is smaller and more discrete. It also stresses a journalistic approach to storytelling, and the involvement of a human editor to shape the final piece.
What assumptions will you test?
One key premise of the project is that wearable technology such as Google Glass can help journalists tell stories in new ways.
Specifically, we hope that wearable technology might solve two problems faced by journalists filming documentary pieces about interesting people. One, subjects often act more self-consciously when they are followed around with a camera, detracting from the authenticity of the story. Secondly, the reporter is often not with the subject of a story at key moments, leaving gaps in the final piece. We see Google Glass (and potentially other wearable devices), as a way to follow story subjects with a kind of robotic reporting assistant that will occasionally shoot video and even ask them questions about what they’re seeing.
Who is working on the project?
Jeff and Primavera are working together on this project for the class. We’re also working with Scott Greenwald, a PhD student in the MIT Media Lab. He works in the lab’s Fluid Interfaces Group and is a developer of WearScript, which allows rapid app development for Google Glass with Javascript.
What have you made so far?
We have created a rough prototype of the app using WearScript, a system designed to rapidly prototype Glass apps to test them. We have done a couple of initial tests and created a Web site outlining the project: http://wearablediaries.org/ Jeff also presented the idea at a Google Glass hackathon at the MIT Media Lab: http://bit.ly/weartalk
Taking the project further will require creating a more robust Glass app and purchasing Google Glass that are fitted onto less-conspicuous frames than the original design.
Kevin and I have been working on FOLD, a tool that adds structure and context to news stories.
FOLD allows you to expand and contract elements of a story (to get more or less detail), and associates a context bar to each section of the story. A context bar can include many elements, including historical background, maps, photographs, citizen media, videos, or technical descriptions.
From observing people consume news, we recognize that readers spend significant time acquiring contextual information in additional browser tabs, taking their attention away from the story at hand. FOLD offers journalists a way to provide readers with a curated “tangent.”
For the final project, Kevin and I would like to continue our work on FOLD by:
1) Conducting further observations of readers interacting with complex and/or emerging stories so we can see their processes of trying to understand the news (e.g. Do they pull up other sources to look up a specific concept or prior event? If so, how often? Do they give up reading the article altogether? What is their understanding of the article after having read it?)
2) Making changes and improvements to the design based on our observations of readers and feedback from the class
3) Adding an authoring platform (so writers can easily turn plain text and photos/videos into FOLD vertical and horizontal ribbons)
4) Conducting user studies with a few journalists in the class, to see if and how their writing process changes when structuring stories in the FOLD way. Extending from that, we can also see if FOLD changes not only how something is written, but what is written.
5) Re-making an existing story into a FOLD story to create a nice demo of what the tool can do
WikiLeaks has been an important step toward greater transparency and accountability. By publishing leaked documents from governments, corporations and other institutions, WikiLeaks has revealed the power of transparency and openness online. That said, WikiLeaks has some serious flaws with their own transparency, openness of their releases, and methods.
This is an exploration of some of the problems with WikiLeaks through a story of my attempt to analyze the WikiLeaks Global Intelligence Files release. The Global Intelligence Files (GI Files) are a collection of five million emails from the intelligence contractor Stratfor. These emails are from the years 2004 to 2011 and discuss Stratfor’s internal operations.
I was hoping to analyze Stratfor’s communication structures by making a network graph from the GI Files. Email is perfect for this sort of analysis. Someone made a tool called cable2graph for graph analysis of Cablegate, so I planned to adapt that tool for use with emails.
Ideally, I would use all the Stratfor emails for this graph analysis. Unfortunately, WikiLeaks has not released all the Global Intelligence Files yet. They started publishing the GI Files on February 27th, 2012. This was over a year ago. Five million documents is a lot, but after fifteen months only a fraction of the documents have been released. It does not seem like WikiLeaks is seriously trying to release these documents. They have not released any sets of emails since February 2013 and most months only several sets of emails are published. Even considering time spent reviewing documents before release, the release of the GI Files is taking far too long.
The second issue with analyzing the Global Intelligence Files is WikiLeaks’s release strategy. WikiLeaks is working with “more than 25 media partners” to release the documents. These partners get access to the full set of documents. WikiLeaks releases GI Files emails only when a partner writes an article about them. WikiLeaks has released a few hundred sets of these emails so far, but most of these releases only contain a few documents.
This release strategy makes it incredibly difficult to find new stories in released Stratfor emails. After all, the emails are only released when they have been used in a story already. This means there is no obvious way for most WikiLeaks supporters to help with the release and analysis of the GI Files. Partners are invited and must be “a journalist, Professor or Associate Professor at a University or an employee of a human rights organisation.” In some ways, this is worse than a pay wall. Access to the GI Files is restricted and there is no clear way someone can get access.
Despite these difficulties, I thought using network graphs to examine the bigger picture of all the released emails may still reveal some new information. WikiLeaks does very little analysis of most of its documents. For the GI Files, WikiLeaks seems to rely entirely on the analyses done by their media partners. Unfortunately, WikiLeaks makes it difficult to analyze most of their releases. A few, like Cablegate, are accessible in machine readable formats. People have used these formats to analyzethedocumentsininterestingways.
Most WikiLeaks releases are not accessible in machine readable formats. There are no machine readable versions of the Global Intelligence Files. As of this month, the US government has better policies for releasing machine readable data than WikiLeaks. This new policy is a great step forward for the US government, but it is a huge failure for WikiLeaks that they are now behind the US government on certain transparency policies.
To get the GI Files email data in machine readable format, I wrote a scraper. I was able to scrape the email subjects, dates, IDs, and text. Then I ran into yet another issue. Where the email addresses in the to and from fields should have been in the HTML, there was a CloudFlare ScrapeShield script. The purpose of ScrapeShield is to stop spam bots from collecting email addresses from websites. This is a good thing, but ScrapeShield becomes problematic when it gets in the way of analysis of documents. Is it more important that Stratfor employees get less spam or that people can analyze the WikiLeaks documents? I would generally say the latter since extra spam is a minor inconvenience (and most is caught by spam filters), but Stratfor employees have no say in this, so that complicates the situation.
While not ideal, one solution is for WikiLeaks to give only their media partners access to machine readable data or have some method of requesting it. Not only does WikiLeaks not give media partners access to machine readable data, but they actively ban their partners from scraping the documents. This ban on scraping and running scripts greatly limits the types of analysis their partners can conduct. It may also make it more time consuming to find documents to write about where network and content analysis could reveal interesting sets of emails faster. This restrictive partnership system may be why so few of the GI Files emails have been released so far.
Network analysis is not possible without the to and from fields of the emails. I found a way where it may be possible to get the to and from emails by converting the emails to PDFs and then scraping the PDFs, but this would be extremely difficult. PDF scraping itself is hard, but automatically scraping thousands of slightly different PDFs may not be possible. Thus, I gave up on the network analysis idea.
WikiLeaks is not only failing to make it easy to help with document release and analysis, but they actively impede anyone who wants to help, including their own partners. While WikiLeaks has done some great things for transparency, the organization has some serious problems with secrecy. This secrecy spreads to their releases and perpetuates closed documents behind walls. As the purpose of WikiLeaks is encouraging greater transparency and accountability through release of restricted information, restricting access to that information again defeats the purpose.
WikiLeaks is dying and if it does not change its methods it will die. Regardless of what happens, some of the successesof WikiLeaks have shown the world the power of leaking and transparency. These successful releases are not the norm. Most of the WikiLeaks releases and those of other transparency initiatives are rendered useless by the issues discussed above and others.
We can do better. I am not sure exactly what will work, but there are a few tasks I think a successful solution to these problems will contain. I have been working on a transparency platform that addresses the issues described above and other problems I have noticed with leaking and other transparency initiatives.
Define
When examining any leaked or released information, it helps to define what information the investigative group has and what information it needs. There seem to be two main parts to this defining stage and tools that could help with the process, defining investigative questions and steps to answer those questions.
First, it may be helpful to define the questions the group wants to answer about the information. These questions will likely change throughout the process, but defining some questions upfront can help guide the investigation. A platform that lets people post, edit, and add answers to questions is a simple place to start for investigation of released documents.
Second, the group needs to define how they will answer each question. This could mean determining what information they need, how they will collect that information, and what types of analysis they will conduct with the information. Again, these steps may change throughout the process, but a list of clearly defined steps to answer the investigation’s questions may be a good starting point. Clearly defined steps or tasks are also helpful because they make it clear how supporters can help with the investigation. That clear path to involvement alone would be a huge improvement over WikiLeaks where supporters struggle to figure out how they can help. Simple task management software could allow people to define and allocate these steps to answer each question. It may even be possible to suggest steps based on the wording of the question or steps already entered. Suggestions like this would make it easier for people to figure out how to conduct the investigation.
Collect
Some investigations may start around a particular set of documents the group has already. This often seems to be the case with leaking and whistleblowing. In this case, it may be helpful for these documents to be uploaded in one place so people can search and analyze them. These documents should also be uploaded in a machine readable format for analysis. These two goals can be accomplished with a combination of a searchable document storage/upload system and scrapers.
The group examining the released documents may want to collect related information like interviews, data sets, documents released by other organizations, or user contributed data. Or maybe someone has questions and has no documents to start with yet when finding an answer. These additional documents could also be uploaded to the central storage/upload system to make it easier to search, combine, and analyze all the information. This document collection system could go a step further make it easier to find documents with options to pull information from common data sources like government data APIs, Wikipedia, and search results at the click of a button. Additionally, people helping with the investigation could use a browser plugin to easily send documents or scrape web pages they find online to the information storage system.
Sometimes a whistleblower may want to upload related documents anonymously. An anonymoussubmission system could be adapted to send documents directly to the storage/upload system. There could also be options for automatic redaction of names (or emails) in the documents submitted by whistleblowers (perhaps with a way some people can access the full data).
After all of this information is uploaded, it would be nice if it could be used outside this single investigation. Thus, it could be helpful to give the person uploading documents the option to share them with others using the same document collection system. This sharing system would make it easy to import documents and data into a new investigation or instance of the information collection and storage system.
Analyze
Collecting and releasing documents only goes so far. To use information, people need to understand it. The analysis used to understand the documents includes anything from reading and discussing the documents to combining different forms of information and using content or network analysis programs. The most helpful type of analysis will vary based on the type of information available and questions asked.
Plenty of analysis tools exist, but a toolkit of many different analysis tools (existing and new) that allows these tools to be easily linked together and use information from the document collection system would make them easier to use and more powerful. For example, users could set one tool to parse a set of data from the document collection system and pass the output of that tool to another that does content analysis to determine relevant Wikipedia pages and then have another tool pull dates from those pages. Another tool could then format the dates and the dates in the original data into the format required by TimelineJS and then have TimelineJS with those dates embedded on the analysis/results page. Each of these tools could be used on their own or with different tools as well. Such an analysis toolkit would make existing tools easier to use and make them more powerful by allowing people to hook them together without coding. People who can code could upload their own tools for others to use or modify existing ones.
Release
While the system described above may help with collecting and analyzing information, it may still be too time consuming and complicated for someone who just wants to learn about a situation and not take part in the investigation. With all the questions, documents, and analysis in one place, a program could easily take all of these and reformat them for a release page. This release page could have summaries and basic information on the findings at the top with the full details from the investigation, analysis, and full documents underneath. While the investigation system would be structured to make it easy to contribute, the release page would be structured to make the information easy to read and understand.
No matter how nice the release system and investigation platform is, few people will find the release pages on their own. People need to write articles about the release and share links to the release page. WikiLeaks’s release model of having media partners write articles is not all bad. I think media partners can be a helpful part of a disclosure system so long as documents are not only released when media partners write articles and they have the tools to help with analysis.
Using the Information
Collecting documents, analyzing them, and releasing more understandable information is not helpful if no one uses the information for anything. Using the released information can take many forms, so I am focusing on the first steps mostly for now. That said, the same structure that helps people define questions and steps to answer them could be used to set specific goals for change or greater awareness based on the released information.
Next Steps
Tools exist to help with all of the steps described above. Some people already use these to examine leaked or released documents. Unfortunately, these tools are often difficult to use and identifying and using many different tools or methods quickly becomes cumbersome, so in many cases they are not used at all. I am building the system I described above. This system integrates both existing tools and new ones in a modular and extensible platform for collaborative investigation.
Hopefully this platform will at least make it easier for organizations already releasing or analyzing leaked and released documents to conduct good analyses. Ideally, this system will be directly integrated with sites releasing documents (both leaking organizations and government transparency initiatives) to provide a platform for collaborative investigation and civic engagement between different groups and individuals.
For now, you have to run the scraper on ScraperWiki, but I hope to integrate it more directly with Transparency Toolkit in the future. The main Transparency Toolkit system can be tested on the demo site (where I’ve uploaded some of the GI Files) or downloaded from Github. The TimelineGen gem can be used as a gem or downloaded from Github. Currently you can only make timelines directly on Transparency Toolkit from specific GI Files release pages, but TimelineGen has methods that can be used in more general cases (I’m still hooking them together manually for the timeline embed).
This is a tutorial/demo video that shows how this works-
If you want to use Transparency Toolkit to make timelines of WikiLeaks GI Files releases, some instructions are below. At this point, it is helpful if you know the basics of how to use ScraperWiki.
2. Ask a question or set a goal by typing in the box at the top (or skip this if you want to add a task to an existing question).
3. Click the + button next to the question to which you want to add a task and add a task by typing in the box that says “Add a task”. Tasks are clearly actionable steps for answering the question, like making a timeline of a set of emails.
4. Go to the GI Files release page and click on one of the links to view a set of emails that was released. Copy the URL of the page with the set of emails.
5. Go to the GI Files scraper and scroll down to line 99 right under ”#To get all emails for a single gifiles release:”. Then replace the URL in the getEmail(url) method with the URL you copied in step 4.
6. Save and run the scraper.
7. Click “Back to scraper overview” in the top right corner. Then click the Download menu and choose “As a JSON file”. Be sure to clear the old data before running the scraper again.
8. Go back to the task page you created on Transparency Toolkit in step 3. Click the “Contribute results from task” field and type anything you want about the results.
9. Click the Browse button and select the JSON you downloaded in step 7. Submit the results
10. You should see a timeline of the emails on the release page you specified. You can see an example timeline here as well.
Rochelle Sharpe, Adrienne Debigare, and David Larochelle
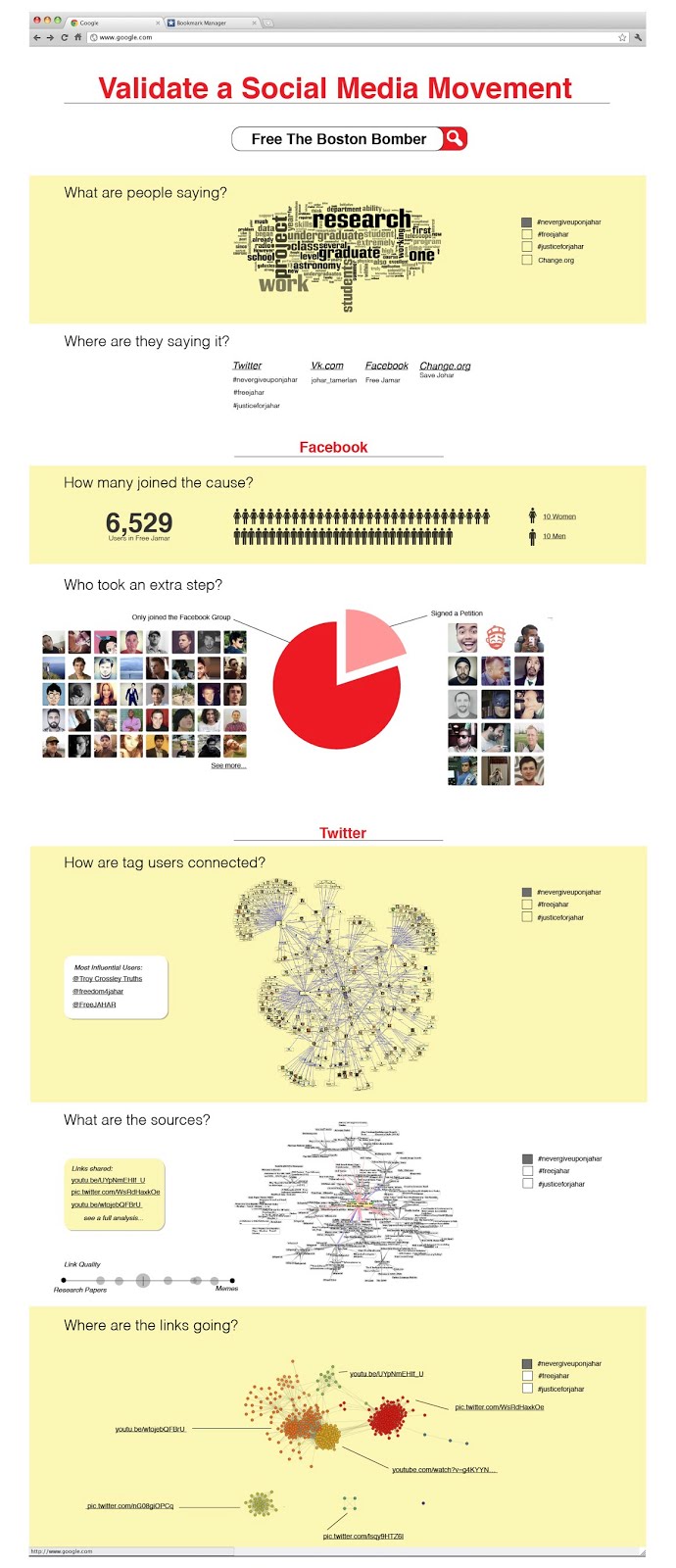
It didn’t take long for conspiracy theories about the Boston marathon bombers to take hold on social media.
On the same day Dzhokhar Tsarnaev was captured in Watertown, Ma, the Twitter feed “FreeJahar got created – and it’s been growing ever since.
“Look at his hair,” someone tweeted earlier today. “Would a terrorist have nice hair?”
While hundreds of Twitter followers and more than 6,000 fans of a Facebook page asking whether Jahar has been set up, a bigger question emerges about social media. How can the public possibly know whether the conspiracy theorists are a growing movement or merely a tiny band of people who’ve figured out how to hijack social media to amplify its message?
We propose a tool to assess the legitimacy of opinions spread on social media. It would essentially apply the age-old basic journalism questions, the who, what, when, where, why, to assess the validity of social media posts.
How many supporters are needed before a movement is significant? The White House has struggled with this question with their We the People petitions. They initially required 5,000 signatures within 30 days to get a response. After being inundated with more petitions than they could handle, they raised the number to 25,000 and then to 100,000.
When covering an emerging social movement online, it is important to know who actually supports it. We developed a prototype tool to analyze the membership of the main Jamar Facebook group. Although the New York Post portrayed supporters as smitten teenage girls, we found that the Facebook group was overwhelmingly male. We also found that the overwhelming majority of members were likely to be US based. (The facebook group went invite only before we could perform additional analysis.)
Encouraged by the success of our prototype, we propose the creation of a more powerful suite of tools for analyzing social media movements. These tools would allow journalists to quickly analyze a social movement quantitatively rather than just qualitatively.
The proposed tool suite would be able to show the following:
Word clouds based on the contents of tweets containing a hashtag or posts in a facebook group.
What social media services the conversation was taking place on.
How many users took the extra step of signing an online petition.
How users of a twitter hashtag are connected
What types of sources are being cited — research papers, mainstream media articles, blogs, memes, etc.
While browsing and studying maps for our final project, Catherine and I started compiling a mapping handbook for journalists. It’s far from complete, but we wanted to share an initial blog post and ask for your thoughts and feedback. Rather than focus on technical details (many of which are already covered in other blogs or places like the Data Journalism Handbook), we focused on questions a journalist might ask before making a map in the first place.
We’d love to hear your feedback, additional examples or questions.
For our final project, Luisa and I created a critical geography of the news coverage of the Boston Marathon bombings in comparison with other crises that happened that week. We put our main blog post writing up our findings on the Center for Civic Media’s blog. We created a poster and an online tool where you can explore the maps and data related to this research.