Hypotheses
I come from an engineering/computer science background, so my interest in this assignment was mapping my news data programatically and doing interesting data visualizations. I’ve learned that data visualization is often easiest if you start with a hypothesis, because then you know what you’re looking for, and even the lack of a result tells you something. So I made two hypotheses about my news reading habits over the past week:
Hypothesis #1: I get most of my news from social sources, such as Facebook & Twitter. The ‘legitimate’ news source I read most often is the New York Times, not because I visit the website, but because the links that are shared tend to be from there. However, all of my news reading is dwarfed by Reddit usage (which is mostly not due to .
Hypothesis #2: A large amount of news that I’ve read has to do with the Chapel Hill tragedy. Being a practicing Muslim and very involved in the community, the story of 3 muslims being killed execution-style in a possible hate crime has dominated my news feed for the past week.
Methods
Empirically, I know that I do almost all of my news reading online and on my computer, so I only analyzed data from my laptop computer.
I installed RescueTime and other existing tracking options, but found that they not useful in tracking the sources of my traffic, especially only for news. Instead, I decided to query my Chrome Search history to be able to trace my activity. This was done using node.js and sqlite3 to make it easily reproducable on other people’s computers if the data is interesting.
The GitHub repo for the code is here: https://github.com/ThariqS/FutureofNews-MediaVisualizations. It is currently poorly documented and doesn’t show you visualizations (only results) but I’m uploading it on GitHub to motivate myself to polish it up.
Results
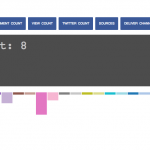
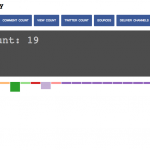
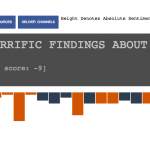
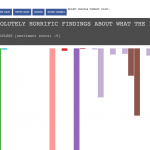
Finding #1: Sports dominated my history results. 81% of my news-related history entries were sports related from ESPN & Reddit (I read a large amount of e-sports news on Reddit). The nature of the way I read sports news is fundamentally different from how I read traditional news. Sports games change more often than news stories, more time is spent tracking and staying updated (over 80% of my news-related history was for sport stories).
Finding #2: The news sites I visited

Finding #3: The sources of my news could be divided into 4 different areas: (url bar, google, social and other news stories). Interestingly, I found that the largest trigger for me to read news was to be on a news site, many of the articles I read came as branches off news sites I was already on. Google and Twitter were close seconds. Unsurprisingly, little of my news came from me directly going to the urlbar and typing in ‘newyorktimes.com’.
Disappointingly, though I think much of my news is through Facebook, I was unable to get exact numbers on Facebook usage, due to a limitation of the Chrome history storage and how facebook processes links.

Finding #4: Word Cloud/Topic Generation
Discerning the topics of the news articles I read was difficult, given that I only had access to the titles of the pages. Without being able to apply some more advanced natural language processing techniques, I simply made a wordcloud out of the title words. Some key highlights that stick out to me are: “Hackers”, “Isis”, “Senate”, “Muslim”, “Storm”

Further Work & Weaknesses:
I know intuitively that a large amount of my news comes from Facebook, but it appears that this method I used is inaccurate in tracking links originating from Facebook.
Secondly, I would be interested in the news I read through osmosis, i.e. news I see through scrolling through Twitter & Facebook. I may be aware of these headlines even if I don’t know anything more than the introductory blurb for the story.